The Prompt Economy
Prompt Marketplaces
Platforms like PromptBase, PromptHero, and CivitAI let creators buy, sell, and share text prompts for AI image generation.
Prompts as IP
Sellers assert intellectual property rights over their prompts, claiming them as proprietary creative assets. Platforms keep the actual prompt hidden until purchase.
The Vulnerability
Every marketplace listing shows sample images. Can someone reverse-engineer the secret prompt just by looking at those images?
What is Prompt Inference?
Prompt Anatomy
Prompts have a subject (what it depicts: cat, robot, astronaut…) and one or more modifiers (style, lighting, mood, color palette, medium…)
Even small modifier changes radically alter the image — capturing stylistic intent from visuals alone is deeply ambiguous.

Datasets & Models
Four txt2img Models
- MidJourney v5 — closed-source, Discord interface; highly stylized
- Stable Diffusion XL (SDXL) — open-source transformer-based
- DreamShaper XL — SDXL fine-tune for photo-realistic fantasy imagery
- Realistic Vision v5 — SD 1.5 fine-tune for photo-realism
CFG Scale: 5 · Sampling Steps: 40 · Euler sampler
MidJourney used default model settings (parameters not user-controllable)
Participant Profile (n=230)
- Most aged 18–44; 59% male, 38% female, 2% other
- Moderate familiarity with generative AI: ~⅓ were only "slightly familiar" with image generation tools
- Participants saw 5 images each from controlled + uncontrolled sets and typed their best-guess prompts
Responses filtered: excluded entries missing subject or modifier, containing random/blank text, or non-English




A Novel Evaluation Framework: Distribution-Level Inference
The Problem with Single-Image Comparison
txt2img models are stochastic — the same prompt produces different images each run. A single lucky match doesn't prove prompt equivalence.
Our Approach: Distributional Equivalence
For each prompt, generate 200 reference images (original prompt) and 50 inferred images (participant prompt). Treat each as a sample from a probability distribution.
Kolmogorov–Smirnov Test
Two-sample KS test checks whether the two similarity-score distributions are statistically indistinguishable (p > 0.05 = a "hit").
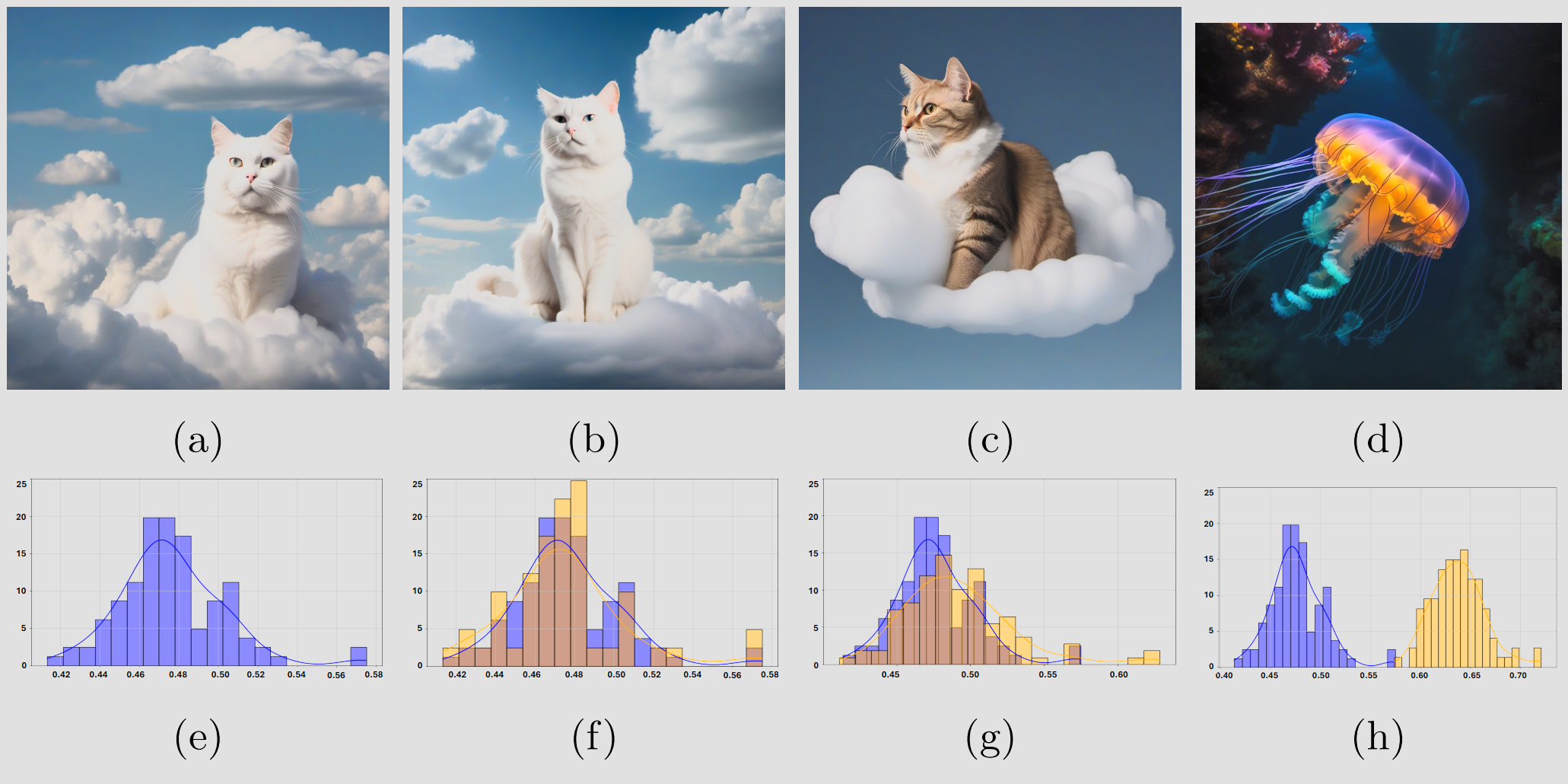
Fig. 6 — Same prompt (a,b) → overlapping distributions (f); different prompt (d) → diverging distribution (h). A hit = distributions are statistically indistinguishable (p > 0.05).
Q&A
Full Paper Pre-print

khoitrinh@ou.edu
EvoMUSART 2026